Protocol Buffers 和 JSON 之间的如何选择

1. 概述
Protocol Buffers (Protobuf) 和 JSON 是流行的数据系列化格式,但在可读性、性能、效率和大小方面存在显著差异。
本教程比较了这些格式并对它们进行权衡。这将帮助我们根据用例做出明智的决定。
2. 可读性和 Schema 要求
Protobuf 需要预定义的 schema 来定义数据结构。这是严格要求的,没有它,应用不能解析二进制数据。
为更好理解,让我们来看看一个示例文件 schema.proto:
syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
string email = 3;
}
message UserList {
repeated User users = 1;
}如果我们进一步看一下以 base64 编码的 Protobuf 信息示例,它对人类缺乏可读性:
ChwKBUFsaWNlEB4aEWFsaWNlQGV4YW1wbGUuY29tChgKA0JvYhAZGg9ib2JAZXhhbXBsZS5jb20=我们的应用序只能结合 schema 文件来解释这些数据。
另一方面,如果我们用 JSON 格式表示相同的数据,我们可以在不依赖任何严格 schema 的情况下理解这些数据:
{
"users": [
{
"name": "Alice",
"age": 30,
"email": "alice@example.com"
},
{
"name": "Bob",
"age": 25,
"email": "bob@example.com"
}
]
}另外,这些编码数据完全是人类可读的。
但是,如果我们的项目需要严格验证 JSON 数据,我们可以使用 JSON Schema,这是一个用于定义和验证 JSON 数据结构的强大工具。虽然它提供了显著的好处,但它的使用是可选的。
3. Schema 演变
Protobuf 强制执行严格的 shcema,确保强大的数据完整性,而 JSON 可以 schema-on-read 数据处理。让我们了解这两种数据格式如何以不同的方式支持底层数据 schema 的演变。
3.1. 用于消费者解析的向后兼容性
向后兼容性意味着新的代码仍然可以读取旧代码编写的数据。因此,它要求新版本正确地反序列化使用旧 schema 版本序列化的数据。
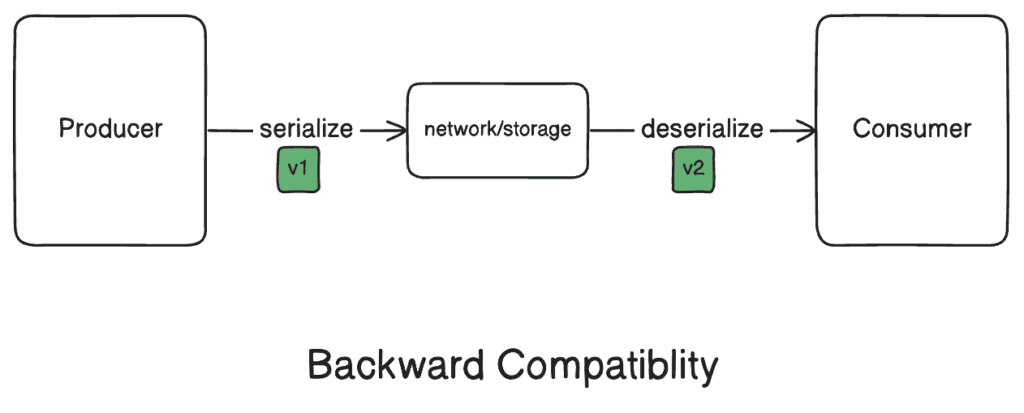
为了确保 JSON 的向后兼容性,应用应设计程在反序列化过程中忽略无法识别的字段。此外,消费者应该为任何未设置的字段提供默认值。使用 Protocol Buffers,我们可以直接在 schema 中添加默认值,从而增强兼容性并简化数据处理。
此外,Protobuf 的任何 schema 更改都必须遵循最佳实践,以保持向后兼容性。如果我们要添加一个新字段,我们必须使用一个以前没有使用过的唯一字段号。同样,我们需要弃用未使用的字段并保留它们,以防止重复使用可能破坏向后兼容性的字段号。
虽然我们可以在使用这两种格式时保持向后兼容性,但 protocol buffers 的机制更正式、更严格。
3.2. 用于消费者解析的向前兼容性
向前兼容性指的是老代码可以读取新代码编写的数据。它要求老版本正确反系列化新版 schema 系列化的数据。
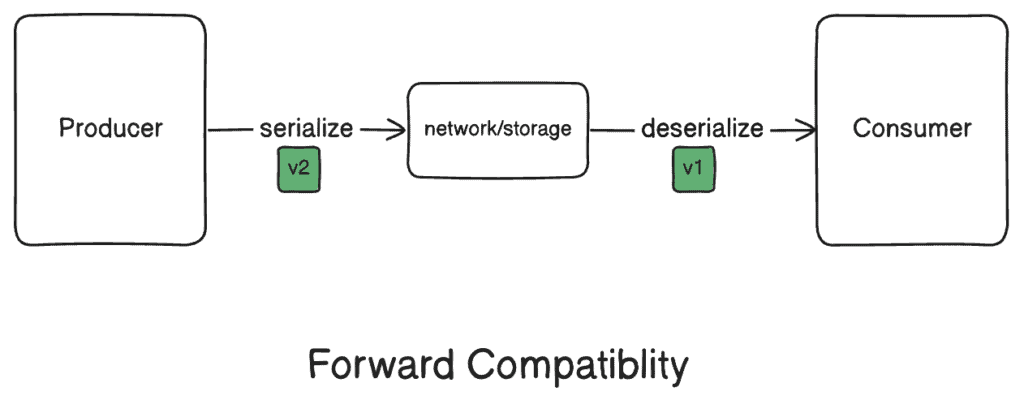
由于旧代码无法预测可能发生的数据语义的所有潜在变化,因此保持前向兼容性变得更加棘手。为了向前兼容,旧代码必须忽略未知属性,并依赖新 schema 来保留原始数据语义。
在 JSON 的情况下,应用的设计应该明确地忽略未知字段,这对于大多数 JSON 解析器来说很容易实现。相反,Protocol Buffers 具有忽略未知字段的内置功能。因此,protobufs 可以在保证未知字段被忽略的情况下演化。
最后,值得注意的是,在这两种情况下,删除必填字段都会破坏前向兼容性。因此,建议的做法是弃用字段并逐步删除它们。对于 JSON,一种常见的做法是弃用文档中的字段并与消费者沟通。而 Protocol Buffers 允许一种更正式的机制来弃用 shema 定义中的字段。
4. 序列化、反序列化和性能
JSON 序列化涉及将对象转换为基于文本的格式。而 Protobuf 序列化将对象转换为紧凑的二进制格式,同时遵守 .proto schema 文件中的定义。
由于 Protobuf 可以引用 schema 来标识字段名,因此在序列化时不需要将其与数据一起保留。因此,Protobuf 格式比 JSON 更节省空间,因为 JSON 保留了字段名。
设计上,Protobuf 在效率和性能方面通常优于JSON。它通常占用较少的存储空间,并且通常比 JSON 数据格式更快地完成序列化和反序列化过程。
5. 何时使用 JSON
JSON 是 web API 的事实标准,尤其是 RESTful 服务。这主要是由于其丰富的工具、库生态系统以及与 JavaScript 的固有兼容性。
此外,基于文本的特性使其易于调试和编辑。因此,使用 JSON 作为配置数据是一种自然的选择,因为配置应该易于人类理解和编辑。
另一个更倾向于使用 JSON 格式的有趣用例是日志记录。由于其无 schema 的特性,它在将不同应用程序的日志收集到集中位置时提供了极大的灵活性,而无需维护严格的 schema。
最后,值得注意的是,在使用 Protobuf 时,需要一个特殊的 schema 感知客户端和额外的工具,而对于 JSON,不需要特殊的客户端,因为 JSON 是纯文本格式。因此,在开发原型或 MVP 解决方案时,我们可能会从 JSON 格式中受益,因为它允许我们以更少的努力引入更改。
6. 何时使用 Protocol Buffers
Protocol Buffers 对于网络上的存储和传输非常有效。此外,它们通过 schema 定义强制执行严格的数据完整性规则。因此,我们可能会从这些用例中受益。
处理实时分析、游戏和金融系统的应用预期需要超高性能。因此,这种应用场景下,我们必须评估使用 Protobuf 的可能性,特别是对于内部通信。
此外,分布式数据库系统可以从 Protobuf 的小内存占用中受益。因此,Protocol Buffers 是编码数据和元数据的绝佳选择,可实现高效的数据存储和高性能的数据访问。
7. 小结
本文中,我们探讨了 JSON 和 Protocol Buffers 数据格式之间的关键差异,以便在为我们的应用程序制定数据编码策略时做出明智的决策。
JSON 的可读性和灵活性使其成为 web API、配置文件和日志记录等用例的理想选择。相比之下,Protocol Buffers 提供了卓越的性能和效率,使其适用于实时分析、游戏和分布式存储系统。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博