使用 Langchain4j 和 MongoDB Atlas 在 Java 中创建 AI 聊天机器人

1. 概述
聊天机器人(Chatbot)系统通过提供快速智能的响应提高了用户体验,使得互动更加高效。
本文中,我们将使用 Langchain4j 和 MongoDB Altas 一起创建聊天机器人。
LangChain4j 是一个受 LangChain 启发的 Java 库,旨在帮助使用 LLM 构建基于 AI 的应用程序。我们用它来开发聊天机器人、摘要引擎或智能搜索系统等应用。
我们将使用 MongoDB Atlas 向量搜索,使我们的聊天机器人能够根据含义而不仅仅是关键字检索相关信息。传统的基于关键字的搜索方法依赖于精确的单词匹配,当用户以不同的方式表达问题或使用同义词时,通常会导致不相关的结果。
通过使用向量存储和向量搜索,我们的应用将用户查询的含义与存储的内容进行比较,将两者映射到高维向量空间中。这使得聊天机器人能够以更高的上下文准确性理解和回应复杂的自然语言问题,即使源内容中没有出现确切的单词。因此,我们实现了更多的上下文感知结果。
2. AI 聊天机器人应用架构
我们先来看一下应用组件:

我们的应用使用 HTTP 终端以聊天机器人进行交互。它有两个流程:文档家长流程和聊天机器人流程。
对于文档加载流,我们将使用一个文章数据集。然后使用 Embedding 模型生成向量嵌入。最后,我们将这些 Embedding 和数据一起存储在 MongoDB 中。这些 Embedding 表示的是文章的语义化内容,使得相似搜索更加高效。
对于聊天机器人流,我们将根据用户输入在 MongoDB 实例中执行相似性搜索,以检索最相关的文档。在此之后,我们将使用检索到的文章作为 LLM 提示的上下文,并根据 LLM 输出生成聊天机器人的响应。
3. 依赖和配置
由于我们将创建 HTTP API,我们将添加 spring-boot-starter-web 依赖作为开始:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.3.2</version>
</dependency>然后添加 langchain4j-mongodb-atlas 依赖,该依赖提供了用来和 MongoDB 向量存储及 Embedding 模型通信的接口:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mongodb-atlas</artifactId>
<version>1.0.0-beta1</version>
</dependency>最后,添加 langchain4j 依赖。这将提供我们所需的语 Embedding 模型和 LLM 交互的接口:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta1</version>
</dependency>出于演示目的,我们将设置本地 MongoDB 集群。接下来,我们将获得 OpenAI API 密钥。现在,我们可以在 application.properties 文件中配置 MongoDB URL、数据库名称和 OpenAI API密钥:
app.mongodb.url=mongodb://chatbot:password@localhost:27017/admin
app.mongodb.db-name=chatbot_db
app.openai.apiKey=${OPENAI_API_KEY}接下来,创建 ChatBotConfiguration 类。此处,我们将定义 MongoDB 客户端 bean 以及和 Embedding 相关的 bean:
@Configuration
public class ChatBotConfiguration {
@Value("${app.mongodb.url}")
private String mongodbUrl;
@Value("${app.mongodb.db-name}")
private String databaseName;
@Value("${app.openai.apiKey}")
private String apiKey;
@Bean
public MongoClient mongoClient() {
return MongoClients.create(mongodbUrl);
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore(MongoClient mongoClient) {
String collectionName = "embeddings";
String indexName = "embedding";
Long maxResultRatio = 10L;
CreateCollectionOptions createCollectionOptions = new CreateCollectionOptions();
Bson filter = null;
IndexMapping indexMapping = IndexMapping.builder()
.dimension(TEXT_EMBEDDING_3_SMALL.dimension())
.metadataFieldNames(new HashSet<>())
.build();
Boolean createIndex = true;
return new MongoDbEmbeddingStore(
mongoClient,
databaseName,
collectionName,
indexName,
maxResultRatio,
createCollectionOptions,
filter,
indexMapping,
createIndex
);
}
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.modelName(TEXT_EMBEDDING_3_SMALL)
.build();
}
}我们使用 OpenAI text-embedding-3-small 模型创建了 EmbeddingModel。当然,我们也可以根据需求选择其他 Embedding 模型。然后,我们创建 MongoDbEmbeddngStore bean。该存储由 MongoDB Atlas 集合支持,其中嵌入(Embedding)将被保存并索引,以实现快速语义化检索。接下来,我们将 dimension 设置为默认的 text-embedding-3-small 值。使用 EmbeddedModel,我们需要确保创建的向量的维度(dimension)与提到的模型匹配。
4. 加载文档数据到向量存储
我们将使用 MongoDB 的文章作为我们的聊天机器人数据。出于演示目的,我们可以手动下载 Hugging Face 的文章数据集。接下来,我们将把这个数据集保存为 resources 文件夹下的 articles.json 文件。
我们希望在应用启动期间通过将这些文章转换为向量嵌入并将其存储在我们的 MongoDB Atlas 向量存储中来摄取这些文章。
现在,让我们将该属性添加到 application.properties 文件中。我们将使用它来控制是否需要数据加载:
app.load-articles=true4.1. ArticlesRepository
接下来,我们创建 ArticlesRepository,负责读取数据集,生成 Embedding 并存储:
@Component
public class ArticlesRepository {
private static final Logger log = LoggerFactory.getLogger(ArticlesRepository.class);
private final EmbeddingStore<TextSegment> embeddingStore;
private final EmbeddingModel embeddingModel;
private final ObjectMapper objectMapper = new ObjectMapper();
@Autowired
public ArticlesRepository(@Value("${app.load-articles}") Boolean shouldLoadArticles,
EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) throws IOException {
this.embeddingStore = embeddingStore;
this.embeddingModel = embeddingModel;
if (shouldLoadArticles) {
loadArticles();
}
}
}此处我们设置了 EmbeddingStore Embedding 模型,以及一个配置 flag。如果 app.load-article 设置为 true,我们在启动时触发了文档吸收。现在,让我们来实现 loadArticles() 方法:
private void loadArticles() throws IOException {
String resourcePath = "articles.json";
int maxTokensPerChunk = 8000;
int overlapTokens = 800;
List<TextSegment> documents = loadJsonDocuments(resourcePath, maxTokensPerChunk, overlapTokens);
log.info("Documents to store: " + documents.size());
for (TextSegment document : documents) {
Embedding embedding = embeddingModel.embed(document.text()).content();
embeddingStore.add(embedding, document);
}
log.info("Documents are uploaded");
}此处我们使用 loadJsonDocuments() 方法来加载资源目录中存储的数据。我们创建了一组 TextSegment 实例,我们创建了一个 Enbedding 并将其保持在向量存储中。我们将使用 maxTokensPerChunk 变量去指定向量存储文档块中存在的 Token 的最大数量。该值应该小于模型 dimension。同时,我们使用 overlapTokens 来说明文本段之间可能重叠的 token 数量。这有助于我们保持片段之间的上下文。
4.2. loadJsonDocuments() 实现
接下来,我们引入 loadJsonDocuments() 方法,读取原始 JSON 文章,将它们解析到 LangChain4j 文档对象,并准备 Embedding:
private List<TextSegment> loadJsonDocuments(String resourcePath, int maxTokensPerChunk, int overlapTokens) throws IOException {
InputStream inputStream = ArticlesRepository.class.getClassLoader().getResourceAsStream(resourcePath);
if (inputStream == null) {
throw new FileNotFoundException("Resource not found: " + resourcePath);
}
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
int batchSize = 500;
List<Document> batch = new ArrayList<>();
List<TextSegment> textSegments = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
JsonNode jsonNode = objectMapper.readTree(line);
String title = jsonNode.path("title").asText(null);
String body = jsonNode.path("body").asText(null);
JsonNode metadataNode = jsonNode.path("metadata");
if (body != null) {
addDocumentToBatch(title, body, metadataNode, batch);
if (batch.size() >= batchSize) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
batch.clear();
}
}
}
if (!batch.isEmpty()) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
}
return textSegments;
}在这里,我们解析 JSON 文件并迭代每个项目。然后,我们将文章标题、正文和元数据作为文档添加到批处理中。一旦批处理达到 500 个条目(或最后),我们就使用 splitIntoChunks() 将其进行处理,将内容分解为可管理的文本段。该方法返回 TextSegment 对象的完整列表,准备嵌入和存储。
让我们实现 addDocumentToBatch() 方法:
private void addDocumentToBatch(String title, String body, JsonNode metadataNode, List<Document> batch) {
String text = (title != null ? title + "\n\n" + body : body);
Metadata metadata = new Metadata();
if (metadataNode != null && metadataNode.isObject()) {
Iterator<String> fieldNames = metadataNode.fieldNames();
while (fieldNames.hasNext()) {
String fieldName = fieldNames.next();
metadata.put(fieldName, metadataNode.path(fieldName).asText());
}
}
Document document = Document.from(text, metadata);
batch.add(document);
}文章的标题和正文连接成一个文本块。如果我们有元数据,我们会解析字段并将其添加到 metadata 对象中。组合的文本和元数据被包装在一个 Document 对象中,我们将其添加到当前批次中中。
4.3. splitIntoChunks() 实现并获取上传结果
一旦我们将文章组装成 Document 对象,包括内容和元数据,下一步就是将它们拆分为更小的、具有感知 token 的块,这些块与我们的嵌入模型的限制兼容。最后,让我们看看 splitIntoChunks() 是什么样子的:
private List<TextSegment> splitIntoChunks(List<Document> documents, int maxTokensPerChunk, int overlapTokens) {
OpenAiTokenizer tokenizer = new OpenAiTokenizer(OpenAiEmbeddingModelName.TEXT_EMBEDDING_3_SMALL);
DocumentSplitter splitter = DocumentSplitters.recursive(
maxTokensPerChunk,
overlapTokens,
tokenizer
);
List<TextSegment> allSegments = new ArrayList<>();
for (Document document : documents) {
List<TextSegment> segments = splitter.split(document);
allSegments.addAll(segments);
}
return allSegments;
}首先,我们初始化一个与 OpenAI 的 text-embedding-3-small 模型兼容的分词器(tokenizer )。然后,我们使用 DocumentSplitter 将文档分割成块,同时保留相邻块之间的重叠。每个文档都会被处理并拆分为几个 TextSegment 实例,然后返回向量存储(MongoDB)中的嵌入。在引导过程中,我们应该看到以下日志:
存入的文档: 328
存储的 Embedding
此外,如果我们使用 MongoDB Compass 查看存储在 MongoDB 中的内容,我们将看到所有生成嵌入的文档内容:
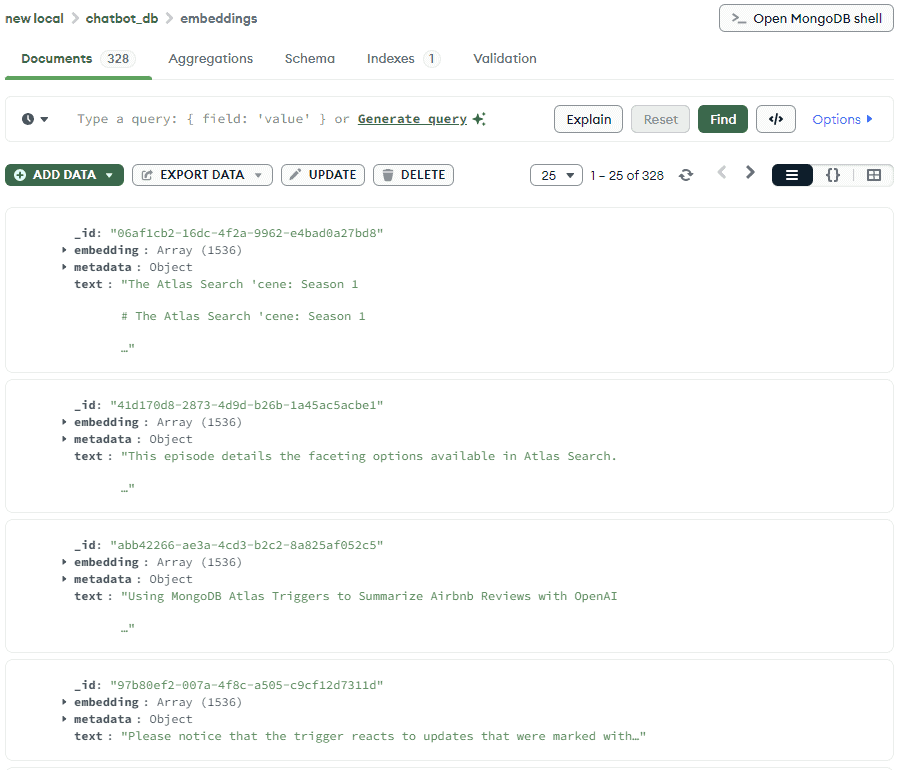
这个处理很重要,因为大部分 Embedding 模型都有token 限制。这意味着一次只有特定数量的数据会被立即嵌入到向量中。分块(chunk)允许我们遵守这些限制,而重叠则有助于我们保持分段之间的连续性。这对于基于段落的内容尤其重要。
出于演示目的,我们仅使用整个数据集的一部分。上传整个数据集可能需要一些时间,需要更多的费用。
5. 聊天机器人 API
接下来,我们来实现聊天机器人API 流程(聊天机器人接口)。我们将创建一些 bean,用来从向量存储中检索文档以及与 LLM 通信、创建上下文感知的响应。最后,我们创建聊天机器人 API 并验证其如何工作的。
5.1. ArticleBasedAssistant 实现
首先我们创建一个 ContentRetriever bean,使用用户输入在 MongoDB Altas 中实现向量搜索:
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.minScore(0.8)
.build();
}这一检索器使用 Embedding
模型来编码用户查询并将其与保存的文章 Embedding 进行比较。同时,我们指定要返回的项目数量和分数,其将控制响应与请求的匹配程度。
接下来,我们创建了一个 ChatLanguageModel bean, 它将基于检索的内容生成响应:
@Bean
public ChatLanguageModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
}在这个 bean 中,我们使用了 gpt-4o-mini 模型,不过我们可以根据需要选择其他模型。
然后,我们将创建一个 ArticleBasedAssistant 接口。此处,我们定义了 answer() 方法,其接收一个文本请求比你返回一个文本响应:
public interface ArticleBasedAssistant {
String answer(String question);
}LangChain4j 通过合并配置的语言模型和内容检索器动态使用还接口。接下来,让我们为助手接口创建一个bean:
@Bean
public ArticleBasedAssistant articleBasedAssistant(ChatLanguageModel chatModel, ContentRetriever contentRetriever) {
return AiServices.builder(ArticleBasedAssistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.build();
}这个设置意味着我们现在可以调用 assistant.answer(“…”), ,而其底层查询是嵌入的且相关文档是从相连存储中获取的。这些文档在 LlM 提示词中用做上下文,生成和返回自然语言答案。
5.2. ChatBotController 实现和测试结果
最后,我们来创建一个 ChatBotController,它将 GET 请求映射到聊天机器人逻辑:
@RestController
public class ChatBotController {
private final ArticleBasedAssistant assistant;
@Autowired
public ChatBotController(ArticleBasedAssistant assistant) {
this.assistant = assistant;
}
@GetMapping("/chat-bot")
public String answer(@RequestParam("question") String question) {
return assistant.answer(question);
}
}这里,我们实现了聊天机器人端点,将其与 ArticleBasedAssistant 集成。这一端点通过问题请求参数接受用户查询,并将其委派给 ArticleBasedAssistant,同时以普通文本的方式返回生成的响应。
让我们调用聊天机器人 API 并看看它的回复:
@AutoConfigureMockMvc
@SpringBootTest(classes = {ChatBotConfiguration.class, ArticlesRepository.class, ChatBotController.class})
class ChatBotLiveTest {
Logger log = LoggerFactory.getLogger(ChatBotLiveTest.class);
@Autowired
private MockMvc mockMvc;
@Test
void givenChatBotApi_whenCallingGetEndpointWithQuestion_thenExpectedAnswersIsPresent() throws Exception {
String chatResponse = mockMvc
.perform(get("/chat-bot")
.param("question", "Steps to implement Spring boot app and MongoDB"))
.andReturn()
.getResponse()
.getContentAsString();
log.info(chatResponse);
Assertions.assertTrue(chatResponse.contains("Step 1"));
}
}在我们的测试中,我们调用了聊天机器人端点并要求其提供使用MongoDB 集成创建Spring Boot 应用的步骤。此后,我们并日志记录了预期的结果。全部响应可以在日志中看到:
To implement a MongoDB Spring Boot Java Book Tracker application, follow these steps. This guide will help you set up a simple CRUD application to manage books, where you can add, edit, and delete book records stored in a MongoDB database.
### Step 1: Set Up Your Environment
1. **Install Java Development Kit (JDK)**:
Make sure you have JDK (Java Development Kit) installed on your machine. You can download it from the [Oracle website](https://www.oracle.com/java/technologies/javase-jdk11-downloads.html) or use OpenJDK.
2. **Install MongoDB**:
Download and install MongoDB from the [MongoDB official website](https://www.mongodb.com/try/download/community). Follow the installation instructions specific to your operating system.
//shortened6. 小结
本文中,我们使用 Langchain4j 和 MongoDB Altas 实现了聊天机器人 web 应用。使用这个应用,我们可以与聊天机器人进行交互,获取上传文章的信息。要做进一步改进,我们可以添加查询预处理并处理摸棱两可的查询。除此之外,我们很容易就可以扩展聊天机器人的答案所基于的数据集。
GitHub 源码:https://github.com/eugenp/tutorials/tree/master/libraries-llms-2。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博