SQL 性能解析:SQL 索引解析

“索引使查询更快”是我见过的对索引最基础的解释。
虽然这句话对索引最重要的一面做了很好的解释,但不幸的是,还不够充分。本文将以不那么粗浅的,也没那么深入细节的方式描述索引结构。它只是为理解 SQL 性能方面提供了足够视野。
索引是数据库中的一个独特的结构,使用 create index 语句创建。它需要自己的硬盘空间,并持有一份索引的表格数据的副本。这意味着索引是纯冗余。创建索引不会改变表格数据;它只是创建了一个新的数据结构指向表格。总之,数据库索引非常像一本书结尾的目录索引,它有自己的空间,高度冗余,指向存储于其他位置的实际信息。
聚簇索引 (SQL Server, MySQL/InnoDB)
在数据库索引中搜索就像在印刷的电话目录中搜索一样。关键的概念是,所有的条目都按定义明确的顺序排序。在排序的数据集中查找容易快捷,因为排序顺序决定了条目的位置。
不过,数据库索引比印刷目录更加复杂,因为它一直在变。为每个改变去更新印刷目录是不可能,因为在现有的条目之间没有多余的空间可以添加新条目。印刷目录通过下次印刷的时候再处理这些累计的更新来绕过这个问题。SQL 数据库却不能等那么久。它必须立即处理插入、删除及更新语句,再不移动大量数据的情况下,保持索引顺序。
数据库联合了两种数据结构,以应对这一挑战:一个双向链表和一个搜索树。这两个数据结构解释了大部分数据库性能特性。
叶节点索引
索引的主要目的是为它所索引的数据提供一个顺序展示。不过,存储数据时没办法按顺序存储,因为插入语句需要移动后面的条目,才能腾出空间给新的条目。移动大量数据是极其耗时的,因此插入会变得非常慢。解决方案是创建和内存物理顺序无关的逻辑顺序。这样的逻辑顺序是通过双向链表建立的。每个节点都链接到两个相邻的条目,就像链条一样。新的节点通过更新链接,使其指向新结点,从而插入到两个现有的节点中间。新结点的物理位置不重要,因为双向链表维护着逻辑顺序。
这样的数据结构叫做双向链表,因为每个结点都指向之前的结点和之后的结点。它使得数据库按需向前或向后读取索引。就这样可以在不移动大量数据的情况下插入新的条目——它只需调整指针。
双向链表也在许多编程语言中用作集合(容器)。
| Programming Language | Name |
|---|---|
| Java | java.util.LinkedList |
| .NET Framework | System.Collections.Generic.LinkedList |
| C++ | std::list |
数据库使用双向链表来连接所谓的索引叶子结点。每个叶几点都存在数据库块或页中;也就是数据库的最小存储单元。所有的索引块的大小相同——一般来说是几kb。数据库尽可能使用每个块中的空间,并且在每个块中存储尽可能多的索引条目。这意味着,索引的顺序在两个不同级别上进行维护:在每个叶结点中使用索引条目,以及叶结点之间使用双向链表。
Figure 1.1 索引叶结点以及对应的表格数据
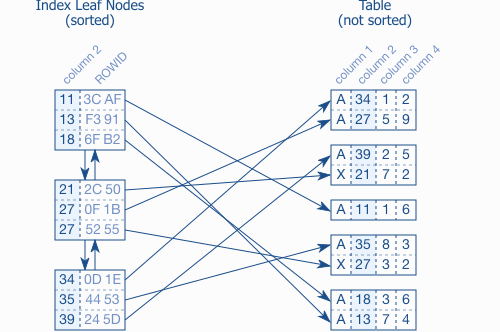
图 1.1 描绘了叶结点和它们和表格数据之间的连接。每个索引条目由其所索引的列(键,column 2)和指向对应的表格行的 ROWID(或RID)组成。不像索引,表数据存储在堆结构中而且没有排序。无论是存在同一个表块中的行之间,还是不同的块之间的连接,都是没有关联的。
搜索树 (B-Tree) 使索引快捷
索引叶结点以任何顺序存储——磁盘的位置与索引顺序的逻辑位置不对应。就像用随机页的电话目录。如果你查找的是 “Smith”,但先在 “Robinson" 处打开了目录,不等于说 Smith 在 Robinson 后面。数据库需要第二个结构去在打乱的页面中快速查找条目:平衡搜索树——即 B 树。
图 1.2 B-tree 结构
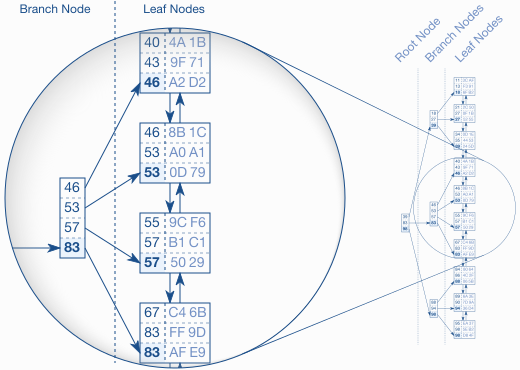
图 1.2 展示了一个有 30 个条目的索引例子。双向链表为叶结点之间建立了逻辑顺序,根结点和分支节点支持叶节点之间的快速搜索。
该图高亮标注了分支节点以及它指向的叶节点。每个分支节点条目对应于相关叶节点中的最大值。以第一个叶节点为例:该节点最大值是 46,因此将其存储在对应分支节点的条目。其他叶节点也是一样,因此分支节点中有这些值:46、53、57、83。根据该方案,建立分支层,直到所有叶节点都被分支节点覆盖。
下一层也是以类似的方式建立,不过位于第一个分支节点的顶部。重复这个过程知道所有的键都进入一个节点,即根几点。该结构就是平衡搜索树,因为树的深度在每个位置都是相同的;根节点和叶节点的距离在任何地方都是相同的。
注意
B树是平衡树,而不是二叉树。
建立完成后,数据库自动维护这些索引。它适用于所有对索引的插入、删除及更新,并保持树的平衡,这就导致了写入操作的维护开销。<修改数据>,对此做了更多解读。
图1.3 B-Tree 遍历

图 1.3 展示了一个索引片段,用来说明对键 ”57“ 的搜索。该树在根节点的左边开始遍历,按升序处理每个条目,直到值大于或等于(≥)搜索项(57)。在图中,这个条目是 83。数据库沿着引用到对应的分支节点并重复该过程直到树遍历获得叶节点。
Important
B-tree 使得数据库能够快速找到叶节点。
树遍历是非常有效的操作,效率如此之高,以至于我将其称为索引的第一生产力。即使在庞大的数据集上,它也几乎能立即工作。这主要是因为树的平衡,它允许用同样的步数访问所有元素;其次是因为树深度的对数(log)增长。这意味着相比于叶节点数,树的深度增长极慢。真实的场景中,百万级数据的索引的树深度是 4 或 5。树深度达到 6 很罕见。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博