使用 Typesense 改进 Laravel 应用搜索的五个实用技巧

Typesense 正在搜索领域掀起波澜。自从 Typesense 被列为 Laravel Scout 的官方支持驱动程序以来,它很快成为希望将全文搜索集成到 Laravel Eloquent 模型中的开发人员的首选。
Typesense 是什么?它是一个快速、开源和自托管的搜索引擎,旨在为 Algolia 和 Meilisearch 等流行解决方案提供强大的替代方案。Typesense 将高性能与易用性相结合,为开发人员提供了构建强大、可扩展的搜索功能的灵活性,而不受许可费或依赖第三方服务的限制。
本文汇编了一些基本技巧,以帮助你使用 Typesense 解决常见的全文搜索任务。今天,我们将深入探讨在 Laravel 应用中安装和配置 Typesense,然后包含如下关键主题:
- 如何对记录进行排序
- 如何有效地使用过滤器(filter)
- 如何调整拼写错误容忍度(typo tolerance)
- 如何访问原始 Typesense 响应
- 以及如何使用 facets 提升过滤
在本文结束时,你将牢牢掌握如何以精确和强大的方式增强网站或应用的搜索功能。
我们开始吧!
如何在 Laravel 项目中安装及配置 Typesense
如果你已经在 Laravel 应用中设置了 Typesense,请跳过这一步。
安装 Typesense
首先,在系统中安装 Typesense。安装过程因操作系统而异,因此请查看 Typesense 文档以获取详细说明。在这里,我们将介绍 Ubuntu 服务器的安装步骤:
curl -O https://dl.typesense.org/releases/27.1/typesense-server-27.1-amd64.deb
sudo apt install ./typesense-server-27.1-amd64.deb安装完后,Typesense 将生成一个 API 密钥,你可以用它来连接到 Laravel 应用。如果你是在 Ubuntu 上安装,请运行以下命令检索:
cat /etc/typesense/typesense-server.ini查找类似下面内容的那行:
api-key = BIO2PGT4B3xpauGBpkIX4p8jAHltKBlxEY5VD3EKFtTZP6jqTip: 如果你通过 Homebrew 在 Mac 上本地安装 Typesense,默认的 API 密钥是
xyz。
此密钥对于 Laravel 应用和 Typesense 之间的安全通信至关重要。保存好它,因为你的 .env 配置需要它。
安装完后,你可以启动 Typesense 服务。在 Ubuntu 上,请运行如下命令:
sudo systemctl start typesense-server.service安装 Laravel Scout
接下来,我们需要一种方法让 Laravel 连接到 Typesense 服务器——输入 Laravel Scout!这个包使 Laravel 模型与搜索引擎的集成变得容易。
你可以在任何现有的 Laravel 应用上安装 Laravel Scout,但在本文中,我们将从一个新的应用开始:
composer create-project laravel/laravel demo-typesense-tips
cd demo-typesense-tips现在我们继续并安装 Laravel Scout:
composer require laravel/scout然后使用 vendor:publish Artisan 命令发布 Scout 配置文件。
php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider"新文件路径未 config/scout.php。我们很快就会编辑该文件。但首先,让我们将这些变量添加到 .env 文件中:
# Our Scout driver is Typesense
SCOUT_DRIVER=typesense
# This is our Typesense API key
TYPESENSE_API_KEY=BIO2PGT4B3xpauGBpkIX4p8jAHltKBlxEY5VD3EKFtTZP6jq完成后,我们就可以开始让我们的模型可搜索了。
让模型可搜索
在你的应用程序中,你可能希望为多个模型(如产品、文章或帖子)添加搜索功能。本文中,让我们想象一下我们有一个电影数据库。我们的目标是使 Moive 模型可搜索。
为了将重点放在搜索提示上,我们将保持数据库结构简单。以下是创建 moives 的迁移示例:
public function up(): void
{
Schema::create('movies', function (Blueprint $table) {
$table->id();
$table->string('title');
$table->enum('rating', ['G', 'PG', 'PG-13', 'R', 'NC-17']);
$table->integer('year');
});
}现在,我们转到模型中:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
use Laravel\Scout\Searchable;
class Movie extends Model
{
use HasFactory, Searchable;
public $timestamps = false;
protected $fillable = ['title', 'rating', 'year'];
public function toSearchableArray(): array
{
return ['id' => (string) $this->id] + $this->toArray();
}
}使模型可搜索的关键细节:
- 使用 Laravel Scout 的
Searchabletrait。 - 定义一个
toSearchableArray方法,该方法返回要索引的字段的关联数组。请注意,Typesense 希望主键是字符串。虽然我们在这里对所有字段进行索引,但你可以排除搜索不需要的任何字段,以节省 Typesense 存储中的空间。
模型就绪后,我们可以在 config/scout.php 中完成配置。打开文件并找到 “Typesense Configuration” 区域。你可以将 client-settings 保留为默认设置,并专注于 model-settings。由于我们想索引和搜索我们的 Movies 模型,以下是我们将设置的配置:
'model-settings' => [
Movie::class => [
'collection-schema' => [
'fields' => [
['name' => 'id', 'type' => 'string'],
['name' => 'title', 'type' => 'string'],
['name' => 'rating', 'type' => 'string'],
['name' => 'year', 'type' => 'int32'],
],
],
'search-parameters' => [
'query_by' => 'title',
],
],
],我们检查一下这个代码:
- 在
collection-schema,我们罗列了想要索引的字段(fields)以及其对于的数据类型。请注意对于year字段我们使用int32,因为 Typesense 不使用integer作为类型而支持int32或int64。 - 在
search-parameters,我们将该字段指定为query_by。此处,我们通过title搜索电影,如果你需要通过多个字段搜索,你可以使用逗号分隔将它们罗列出来(e.g.,title,description)。
设置完成后,是时候将记录从数据库导入 Typesense 了。但首先,让我们确保数据库中有数据!对于本教程,你可以通过使用工厂为电影表添加虚假记录或使用此 seeder 添加示例数据(400 部电影)来填充电影表,这特别适合本指南。
填充完 moives 表后,运行 import 命令:
php artisan scout:import "App\Models\Movie"就是这样。我们准备开始进行测试。
创建搜索端点
我们先创建一个基本的搜索路由。在 routes/web.php 中:
<?php
use Illuminate\Support\Facades\Route;
use App\Http\Controllers\MovieController;
Route::get('movies', [MovieController::class, 'index'])->name('movies.index');然后创建控制器来处理:
<?php
namespace App\Http\Controllers;
use App\Models\Movie;
use Illuminate\Http\Request;
class MovieController extends Controller
{
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))->get();
return $movies;
}
}运行 Laravel 应用并转到 /movies?q=ringo。你可以看到匹配 ”ringo" 的电影的 JSON 响应如下:
[
{
"id": 341,
"title": "The Lord of the Rings: The Two Towers",
"rating": "PG-13",
"year": 2002
},
{
"id": 340,
"title": "The Lord of the Rings: The Return of the King",
"rating": "PG-13",
"year": 2003
},
{
"id": 339,
"title": "The Lord of the Rings: The Fellowship of the Ring",
"rating": "PG-13",
"year": 2001
}
]好极了!Typesense 现在通过 Laravel Scout 与你的 Laravel 应用完全集成。你可以执行搜索并检索匹配的记录。此外,拼写错误容忍是有效的:即使我们搜索了 “ringo”,我们也会得到标题中有 “Ring” 的电影。
但是,我们如何才能使搜索变得更好呢?让我们深入了解一些优化和自定义搜索功能的技巧。
技巧 1:如何排序记录
现在我们检索 "Lord of the Rings" 电影,结果并没有以正确的顺序显示。我们不想看到索伦在佛罗多离开夏尔之前被击败(哦,剧透!),所以让我们解决这个问题。
让我们允许用户发送 sort_field 和 sort_dir 作为查询字符串参数,并使用 Laravel Scout 的 orderBy 方法来正确排序这些记录。
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))
->when($request->has('sort_field'), function ($query, $field) use ($request) {
return $query->orderBy($field, $request->input('sort_order', 'asc'));
})
->get();
return $movies;
}现在,我们来访问 /movies?q=ringo&sort_field=year,我们将按发行顺序列出三部曲。
Typesense 支持 numeric 和 string 字段排序,不过设置上有些不同。
- Numeric 和 boolean 字段默认是可排序的。这意味着无需任何额外的配置,你就可以通过这些字段(e.g.,
year)对结果进行排序。 - String 字段需要做一些设置。默认情况下,他们是不可排序的,因为大量的字符集排序可能导致资源紧张。要让字符串字段可以排序,你需要修改 Typesense 集合 schema。
- 要启用字符串字段的排序功能,请在 schema 中将该字段的
sort选项设置为true:
'collection-schema' => [
'fields' => [
['name' => 'id', 'type' => 'string'],
['name' => 'title', 'type' => 'string', 'sort' => true],记住,无论在何时修改了 schema,你都需要重新导入记录:
php artisan scout:import "App\Models\Movie"要避免需要重新导入,请一开始就将你希望排序的 string 字段的 sort 选项设置为 true。
Tip 2: 如何有效地使用过滤器
想象你要按照年份过滤你的电影搜索结果。首先执行搜索,然后按年份过滤结果,这似乎是合乎逻辑的,如下所示:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))->get();
if ($request->input('year')) {
$movies = $movies->where('year', $request->input('year'));
}
return $movies;
}比如,有了种子数据后,访问 /movies?q=ringo&year=2003 将返回一个结果:The Lord of the Rings: The Return of the King。它匹配了搜索条件(由于类型容忍),并且上线时间为 2003 年。
乍一看,这似乎很完美。然而…事实并非如此。让我解释一下。
让我们添加与搜索词更准确匹配的电影,在标题中添加字符串 “ringo”,例如,十部关于披头士乐队鼓手 Ringo Star r的电影。我不知道谁想看十部关于 Ringo 的电影,但无论如何,让我们添加它们来证明这一点!
// Add 10 movies titled "The Legend of Ringo [1-10]" with a release year of 2024
collect(range(1, 10))->each(fn($i) => Movie::create([
'title' => "The Legend of Ringo $i",
'rating' => 'PG',
'year' => 2024,
]));现在,重新加载 /movies?q=ringo&year=2003。意外的是,The Return of the King 没了!之前还有一个结果,现在却是空数组。为什么会这样?
问题在于如何获取搜索结果。当调用 get 时,只返回结果的第一页。默认情况下,Typesense 将每页限制为 10 条记录。因此,$movies 收藏集合将只包含十个记录。
我们的示例中,这十条记录是最近添加的 2024 年的 Ringo Starr 电影。电影 "The Return of the King" 将掉落到第二页,因为它的标题不完全匹配搜索条件。
按年份 2023 年过滤 $moives 返回了空集合,因为第一页上的记录都不匹配该年份。
要解决这个问题,请在搜索查询上直接应用过滤器。这将利用 Typesense 的过滤器功能,确保结果的准确度是跨越整个数据集而非仅限于第一页。
Laravel Scout 提供了一个 where 方法,允许你在使用 get 执行查询之前,将过滤器作为搜索请求的一部分应用。通过这种方式,Typesense 只返回在分页加入前匹配搜索条件和指定过滤年份的结果。如下例:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))
->when($request->has('year'), function ($query, $year) {
return $query->where('year', $year);
})
->get();
return $movies;
}通过这一修改,过滤作为搜索过程的一部分进行处理,因此即使你的数据集很大,也可以获得完整准确的匹配集。你不需要额外的配置来实现此功能;只需记住在 Typesense 模式(schema)中包含你要筛选的所有字段。
Tip 3: 如何微调拼写容忍度
在许多搜索应用中,用户经常在查询中出现拼写错误或略有拼写变化。Typesense 的拼写错误容忍功能有助于即使拼写有微小差异也能进行匹配。例如,在我们的演示中,搜索 “ringo” 会返回 “Lord of the Rings” 的结果。但是,搜索 “rango” 由于拼写差距较大而无法返回结果。
默认情况下,Typesense 只允许搜索词中出现一个拼写错误。为了使搜索更加宽容,你可以提高拼写容忍度,以容纳进一步偏离的情况。例如,启用最多 2 个拼写错误允许像 “rango” 这样的搜索仍然与 "Lord of the Rings" 电影相匹配。
要配置这个,Laravel Scout 提供了 options 方法,允许你传递额外的选项给 search 驱动。在这种情况下,你想将 num_typos 设置为 2:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))
->options(['num_typos' => 2])
->get();
return $movies;
}通过这一调整,结果将包括与原始搜索词最多 2 个拼写错误的记录。现在搜索 "rango" 将返回 Ringo 的电影、"Lord of the Rings" 电影,甚至"The Lone Ranger"。
提高拼写容忍度可以通过考虑用户错误并提供更相关的结果来增强搜索体验,特别是对于移动用户或更长的搜索词。然而,将拼写错误容忍度设置得太高可能会导致不相关的匹配,从而可能降低搜索结果的准确性。
Tip 4: 如何访问原始 Typesense 响应
Laravel Scout 的 get 方法返回一个模型的集合,使之便于在模板中迭代和渲染,就像 Eloquent 查询结果。不过,如果你需要更多搜索的详细信息,请使用 raw 方法。该方法提供了更全面的 Typesense 响应结果,包括丰富的元数据,如总匹配数、高亮详情、分数信息乃至于以毫秒计时的搜索执行时间。
下例显示如何切换到 raw:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))->raw();
return $movies;
}我们来尝试一下。访问 movies?q=king+return 查看详细 JSON 响应如下:
{
"facet_counts": [],
"found": 1,
"hits": [
{
"document": {
"id": "340",
"rating": "PG-13",
"title": "The Lord of the Rings: The Return of the King",
"year": 2003
},
"highlight": {
"title": {
"matched_tokens": ["Return", "King"],
"snippet": "The Lord of the Rings: The <mark>Return</mark> of the <mark>King</mark>"
}
},
"highlights": [...],
"text_match": 1157451471172665300,
"text_match_info": {
"best_field_score": "2211897737216",
"best_field_weight": 15,
"fields_matched": 1,
"num_tokens_dropped": 0,
"score": "1157451471172665465",
"tokens_matched": 2,
"typo_prefix_score": 0
}
}
],
"out_of": 410,
"page": 1,
"request_params": {...},
"search_cutoff": false,
"search_time_ms": 13
}以下是一些重要的响应组件:
facet_counts: 如果 facets 启用,将其罗列出来。Facets 通过分类组织结果,我们将在下一节中展开。
found: 匹配该查询的文档总数。
hits: 匹配的文档数据。每个 hit 包含:
document: 实际电影数据,包含所有已索引字段。highlight: 使用<mark>标签高亮显示匹配术语的片段。highlights: 所有匹配字段的高亮详情。text_match: 表示匹配度是数值分数。text_match_info: 分数如何计算的详细分解。
out_of: 查询期间评估的文档总数。
page: 说明当前分页,用于大数据集的分页。
request_params: 包含用于实现搜索的参数。
search_cutoff: 显示是否因性能原因,搜索提前停止。false 值意味着评估整个数据集。
search_time_ms: 执行上述所花费的实际,以毫秒计算(e.g., 示例为 13 ms)。
使用 raw 提供了对搜索结果的更深入洞见,包括 Typesense 如何排名和高亮文档。这些数据或有助于:
- 调试: 解决搜索相关性或性能方面的问题。
- 搜索调节:调整设置以获得更好的相关性以及速度。
- 功能开发:构建高级功能,如自定义分页、详细的搜索词高亮或基于 facets 的过滤。
Tip 5: 如何使用 Facet 获得更好的过滤效果
你有没有在网上商店搜索过,看到一个侧边栏,上面有过滤器,显示每个类别中有多少结果?例如,在寻找笔记本电脑时,你可能会看到每个品牌的匹配数量。
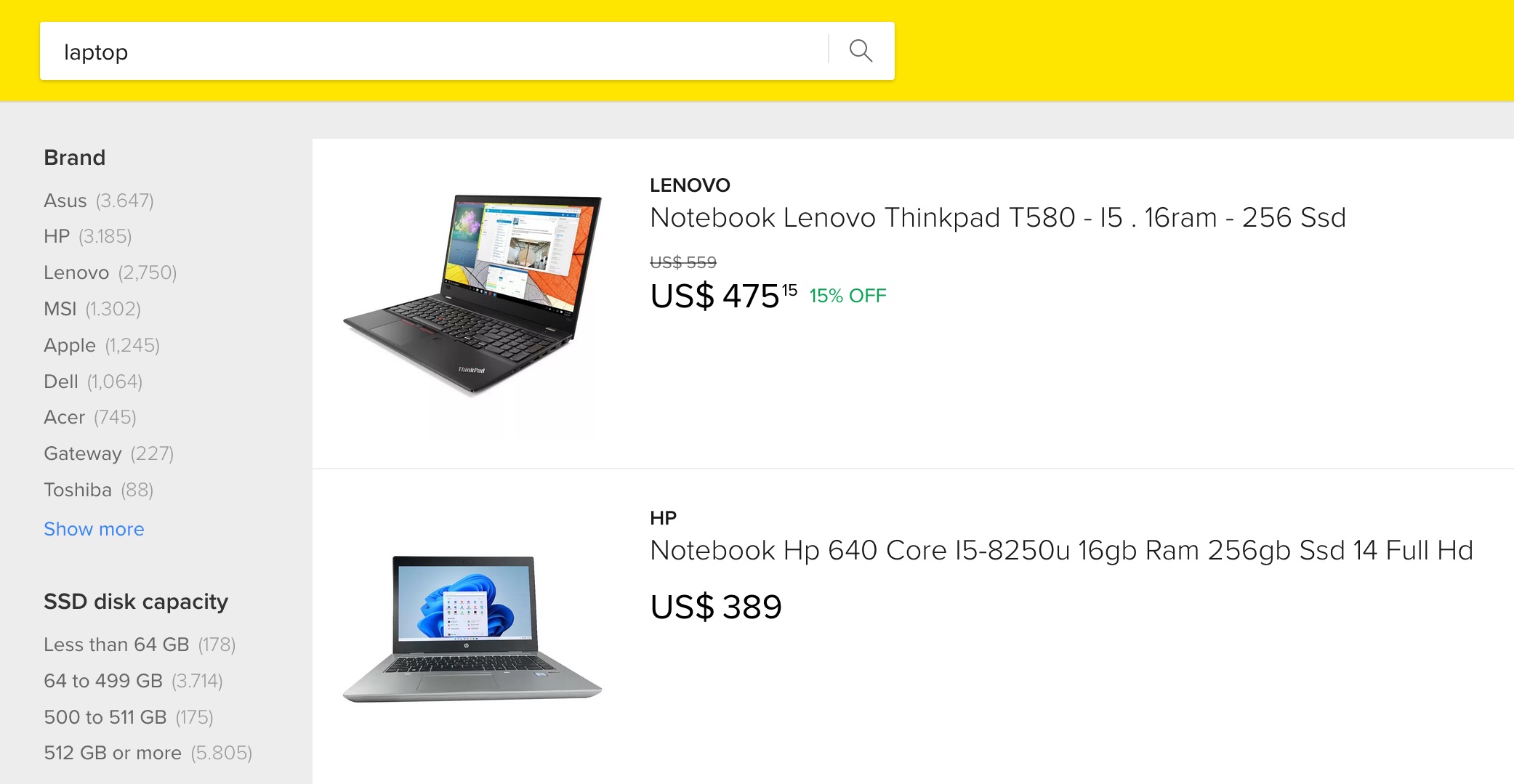
这些快速过滤器称为 facets,是值的聚合计数。向查询中添加 facets 会使 Typesense 返回每个 facet 值的匹配文档计数。Typesense 还计算其他指标,如最小值、最大值、总和和平均值,以及整数字段的计数。
要在 Typesense 中使用 facets,你必须在集合模式(schema)中定义所需的 facets 字段。对于此列中的电影集合,我们可以将 year 和 rating 设置为 facet 字段:
'collection-schema' => [
'fields' => [
['name' => 'id', 'type' => 'string'],
['name' => 'title', 'type' => 'string', 'sort' => true],
['name' => 'year', 'type' => 'int32', 'facet' => true],
['name' => 'rating', 'type' => 'string', 'facet' => true],
],
],接下来,请使用 options 选项来指定哪些字段要 facet_by 并检索 raw 响应对象:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))
->options(['facet_by' => 'year,rating'])
->raw();
return $movies;
}然后,访问 /movies?q=star,我们将看到包含 facet 详情的 JSON 响应:
{
"facet_counts": [
{
"counts": [
{
"count": 2,
"highlighted": "2018",
"value": "2018"
},
{
"count": 2,
"highlighted": "2016",
"value": "2016"
},
...
],
"field_name": "year",
"sampled": false,
"stats": {...}
},
{
"counts": [
{
"count": 12,
"highlighted": "PG",
"value": "PG"
},
{
"count": 11,
"highlighted": "PG-13",
"value": "PG-13"
},
...
],
"field_name": "rating",
"sampled": false,
"stats": {...}
}
],
...
}为允许用户进一步优化结果,我们可以渲染一个模板,其中每个方面值都是一个可点击的链接。首先,让我们更新我们的控制器以接收年份(year)和评级(rating)作为输入,并返回一个视图而不是 JSON 响应:
public function index(Request $request)
{
$movies = Movie::search($request->input('q'))
->options(['facet_by' => 'year,rating'])
->when($request->has('year'), function ($query, $year) {
return $query->where('year', $year);
})
->when($request->has('rating'), function ($query, $rating) {
return $query->where('rating', $rating);
})
->raw();
return view('movies.index', ['movies' => $movies]);
}然后,创建一个 Blade 模板:
@if(!empty($movies['facet_counts']))
<h2>Filters</h2>
@foreach($movies['facet_counts'] as $facet)
<h3>{{ ucfirst($facet['field_name']) }}</h3>
<ul>
@foreach($facet['counts'] as $item)
<li>
<a href="{{ route('movies.index', array_merge(request()->all(), [$facet['field_name'] => $item['value']])) }}">
{{ $item['value'] }} ({{ $item['count'] }})
</a>
</li>
@endforeach
</ul>
@endforeach
@endif
<div class="movies">
<h2>Results</h2>
@if(!empty($movies['hits']))
<ul>
@foreach($movies['hits'] as $hit)
<li class="movie">
<div>Title: {{ $hit['document']['title'] }}</div>
<div>Year: {{ $hit['document']['year'] }}</div>
<div>Rating: {{ $hit['document']['rating'] }}</div>
</li>
@endforeach
</ul>
@else
<p>No movies found.</p>
@endif
</div>现在用户将看见一个过滤器列表,每个都带有优化搜索的链接:
<li><a href="/movies?q=star&year=2016">2016 (2)</a></li>
<li><a href="/movies?q=star&year=2018">2018 (2)</a></li>
...Facets 以结构化和可视化方式帮助用户优化搜索结果,提高搜索功能的可用性和效率,特别是在大型集合中,用户需要优化结果以找到他们想要的内容。
小结
希望本文能助你增强网站上的搜索功能,并作为探索 Typesense 提供的许多功能的起点。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博