数据库以及它背后的存储

先要明确,这里的数据库指的是关系型数据库,即满足 ACID 原则并用 SQL 语言进行操作的持久性(掉电数据不丢)数据库。当然,在追求高并发的过程中,我们将不可避免地接触到内存数据库,但我们一定要知道,内存数据库只是架构设计的一部分,而且不是最重要的部分。
数据库是个大单点
所有 web 系统都会经常面临这种需求:用户要一个一个注册,ID 不能一样;订单要一个一个下,两个订单的信息不能错乱。这其实就是最原始的需求——排队。逻辑上,无论数据库如何拆分,微服务如何设计,一定有一个资源是必须排队的,哪怕我们可以用“现在的时间换未来的时间”这种方式来进行性能优化(后面的文章还会提到),排队是必须存在的。
在常见的 web 系统架构中,关系型数据库就是那个最大的无法拆分的单点:在一个系统内,多个 API 调用所产生的多种行为,最终都要作用到同一张表上,这个系统的运行才能符合逻辑。这也是数据库最核心的价值:API 可以并发,数据库必须排队一个一个来。就像 Redis 之于 golang 协程,就像 Node.js 的单线程排队执行,数据库才是 web 服务的根,是保证最终计算结果符合预期的那个“队列”。
无论进程/线程/协程如何并发,数据库的自增、事务和锁都是原子化的。这种原子化能力恰好是前面的业务服务器能够多台并发的基础,也是多台服务器能够被称为“一个系统”的逻辑基础:如果两个系统的数据库不在一起,那他们就不是一个系统,就像拼多多有 7.5 亿月活用户,淘宝有 8.5 亿,你不能说“拼宝宝”电商系统有 16 亿月活用户一样。
这种哲学思想我们在最后一篇文章的终极高可用架构中还会用到。
数据库为什么是单点
数据库成为数据单点并不是自己决定的,而是系统架构“需要”一个数据单点,而数据库就是为了满足“数据单点”这个需求而被设计出来的。对于大部分需要记录到数据库里的信息来说,基于先来后到进行排队入库都是一个不可妥协的硬需求,否则在逻辑上数据就会出错。对于所谓的 NoSQL 数据库来说,连一个简单的 ID 自增都需要扫描全表才能做到,它是不能承担数据单点角色的。由于它不是为了承担数据单点而设计的,NoSQL 注定只能是关系型数据库用来提升性能的的副手。
关系型数据库的“关系”二字,指的是一个表内部的这些数据之间,拥有行和列两个方向的关系,这其实是另一种形式的“时间换空间”、“空间换时间”思想:提前约束这些数据,让他们以一定的规则存储在一起,写入的时候会慢一点,但是这样调用起来就简单又高效:例如无需全表扫描瞬间找出最大 ID、例如即便将海量数据存储在磁盘上,依然能够以很快的速度检索到满足某个条件的某一行、例如在快速定位到某一行后便可以快速取出连续多行的数据等等。
数据库是一个非常复杂的软件
关系型数据库就像空气一样充斥在后端技术里,但是可能很少有人想过一个惊人的事实:99.9% 使用 MySQL 的系统,其业务代码的复杂度都没有 MySQL 本身的复杂度高。
MySQL 为了实现关系型数据库四大原则,几乎把计算机的每一种资源都用到了极致:进程、线程、多核、网络、寄存器、内存、机械磁盘、固态磁盘。
写到这里,如果我们开始分析 ACID 实现的细节,岂不是落入了俗套,我们要不走寻常路,不背面试八股文,直接分析 MySQL 的底层原理。
数据库这个单点,单在哪里?
一般的技术文章一说到持久性原子性,就是什么 undo log、redo log、多版本并发、锁。我不这么看,下面我们从 MySQL 的基础功能开始思考。
MySQL 是整个 web 系统中唯一一个在意外掉电重启以后,还能保持数据不丢的组件,那它是怎么做到的呢?很简单,基于计算机上唯一一个断电不丢数据的磁盘实现的。所以,不用看什么*do log了,把它们全部当做磁盘文件就行了。
掉电不丢数据是磁盘的重要特性
事实上 MySQL 确实是完全依靠磁盘不丢数据的特性来实现的:如果你执行了update语句,那无论 MySQL 有多少级的缓存,多少种的日志,都得等到它成功将此次数据修改写入到磁盘上以后,才会给客户端返回成功状态。而文件的修改是有队列的,可以保证每一次写操作的可靠性。
当然,这里的写入磁盘,不一定指的是真的存到了那张表对应的数据文件里,也可以是*do log。如果此时服务器意外重启,那在 MySQL 启动以后,它还是会把自己刚才记录的这些*do log里的信息再默默地写入到磁盘上真正的表数据文件里。
“数据库单点单在哪里”的答案已经呼之欲出了:数据库的单点就单在了磁盘上。
存储技术简史
既然数据库的单点就是磁盘,那接下来我们就看看存储技术的发展简史。
集中式存储
集中式存储是一种采用独立的控制器(即计算机)控制大量的硬盘,再通过控制器对外提供多种不同层级的接口(硬件层面的 SAS/FC,软件层面的 SCSI/iSCSI/InfiniBand 等),以同时满足多个客户端、多种不同存储需求的产品。
集中式存储的兴起让IOE中的E大放异彩:就像前面提到的那台价值百万的负载均衡设备一样,EMC 的集中式存储通过双控制器开机热备 + 全冗余网络连接,再配合 SAN 交换机和双 HBA 卡,可以实现全冗余的存储网络架构,它性能很好,可以支持多台服务器连接使用,还非常稳定,只有一个缺点:贵。光是一个普通的 16 口 16G SAN 交换机,价格就已经超过了 40G 以太网交换机(交换容量甚至可以达到50Tbps以上)。更不要说一年也卖不出去几片的 HBA 卡了。而且,集中式存储设备本身更贵,非常贵,比两台标准 x86 服务器还要贵。
为什么集中式存储这么贵呢?因为它用非常高的硬件成本和服务成本,真的解决了大多数企业面临的存储问题:厂家负责上门部署,定期维护,你负责出高价,然后用就行了。集中式存储的本质是用高水平的硬件 + 硬件级全冗余 + 保姆式的技术服务,彻底搞定了存储这件难事。
分布式存储
进入云计算时代,分布式存储大放异彩:反正海量的 x86 服务器已经在机柜里运行着了,为什么不拿出一点点计算资源构建出一个省钱的分布式存储呢?而且从需求的角度来看,云计算的规模是在快速增长的,集中式存储很难满足这种速度的规模扩张。这个时候就需要分布式存储登场了。
分布式存储选择通过海量普通可靠性的硬件 + 软件的方式,将一群 x86 服务器通过以太网或者 InfiniBand 相互连接,将分散在每一台服务器上的机械磁盘和固态磁盘组织到一起,形成一个巨大的硬盘资源池。这个软件定义的存储集群可以做到和集中式存储一样的三高:高可靠性、高可用率、高性能。
高性能靠什么?
虽然我们说分布式存储也有高性能特性,但是,x86 架构下磁盘的性能其实不怎么样。近些年,随着分布式存储的市场占有率越来越高,单系统规模也越来越大,从云计算厂商到服务器厂商,都在想办法提升分布式存储各个部分的性能。除了“网络性能”和“缓存”在快速进步之外,x86 IO 系统的“绝对性能”也在快速进步,现在(2023 年 1 月),我们就站在 x86 IO 性能爆炸的前夜。
小型机的优势,x86 的劣势:IO 性能
《性能之殇》里面提到过 x86 的 IO 性能被架构锁死了¹。而小型机那边,IO 性能的上限非常高,甚至可以为存储子系统配置专门的 CPU。
今天,海量廉价的 x86 服务器集群在越来越快的网卡速率的协助下,在系统总容量和可用性方面已经超过了小型机,让小型机只能在它比较有优势的特定规模、特定行业的业务背后生存。但是,IO 性能不足是 x86 从娘胎里面带出来的弱点,而这个弱点直到最近两年才有了一些改善。
突飞猛进的 PCIe
最近几年,已经沿用了十年的 PCIe 3.0 突然开始大踏步换代,以两年一代的速度疯狂推进,每一次带宽都能翻倍,看起来进步很大。但是,当我们的目光从那惊人的 128GB/s(PCIe 5.0 x32) 的数字上移开后,再仔细地端详一块主板上同时存在的 5.0、4.0 和 3.0 的插槽,就会发现一个更惊人的事实:4.0 和 5.0,是在基础电气属性不变,金手指的数量都完全保持不变的情况下,通过重定时器和重驱动器组件,“强上陆地神仙”的结果。而且,5.0 的插槽它就是 5.0 的,并不能拆成两个 4.0 来用,如果想插 4.0 的设备,也可以,但只能插一个:因为并不是水管变粗了,而是水管支持的流速提高了,这对接收端设备的容错能力也提出了更高的要求。
为什么英特尔一屁股坐到 PCIe 牙膏上了呢?为了下一代超级 IO 架构:CXL。
全村的希望 CXL
虽然第一颗支持 CXL 的服务器 CPU 刚刚上市两个月(AMD EPYC 9004 系列),但不影响 CXL 技术成为“全村的希望”。虽然直到 2019 年英特尔才推出了 CXL 标准,但它不仅推动业界在三年之内火速推出了兼容 CXL 技术的 CPU(而且还是友商开发的),还吸纳了同样技术方向的两个竞争对手:OpenCAPI 联盟和 Gen-Z 联盟,成为了唯一的“新一代通用 IO 标准”。
凭什么呢?就凭 CXL 是英特尔向业界投入的一颗重磅炸弹:一次性放开了从 CPU 直接驱动的 DDR 内存到 NVME SSD 之间广阔的“无人地带”——基于 PCIe 5.0 技术,将 IO 技术推入了一个新时代。别忘了,PCIe 协议也是英特尔定义的。
内存、磁盘正在双向奔赴
最近几年,随着 NVME SSD 在服务器端的普及,内存和磁盘的性能边界正在逐渐模糊:十年前 SATA SSD 刚刚普及的时代,内存带宽和延迟大概为 100GB/S 60ns,而 SATA SSD 为 500MB/S 200μs,速度和延迟分别为1/200和3000倍;而今天内存和 PCIe 4.0 NVME 磁盘的对比为 150GB/S 100ns 和 7GB/S 18μs,这个差距已经缩小到了1/21和180倍。
CXL 补上了“存储器山”上 DDR 内存和 NVME SSD 之间的巨大空隙
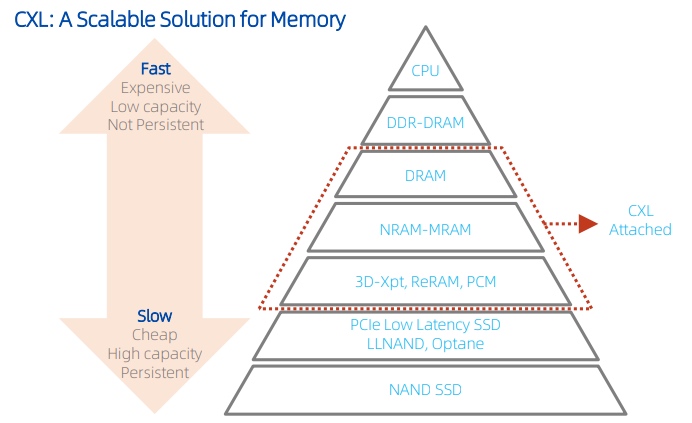
神书《CS:APP》在第六章中提出了著名的“存储器山”理论²:离 CPU 越远的存储器容量更大延迟更高。
两个月前刚刚发布的 AMD 9004 系列处理器引入了 12 通道的 DRAM 内存,这对电路板的设计能力和制造成本提出了非常高的要求,同时对 CPU 内部的内存控制器的驱动能力也提出了很大的挑战,基本可以确定 DRAM 这个将一大块 DRAM 芯片在 Z 轴进行折叠而增加容量的技术已经走到了尽头,以后就是 CXL 的天下了。
CXL 提供了 IO(设备发现、初始化、中断等基础功能)、缓存(低延迟数据复制)、内存(统一地址编码)三个模块,一次性解决了海量内存扩展和多个级别缓存的需求。目前,支持 CXL 1.1 协议的扩展内存已经上市。
未来,双向奔赴的内存和磁盘将在 CXL 技术里胜利会师:容量和延迟的分布将会更加均匀,系统的宏观性能将进一步提升。
奋三世之余烈的终极目标
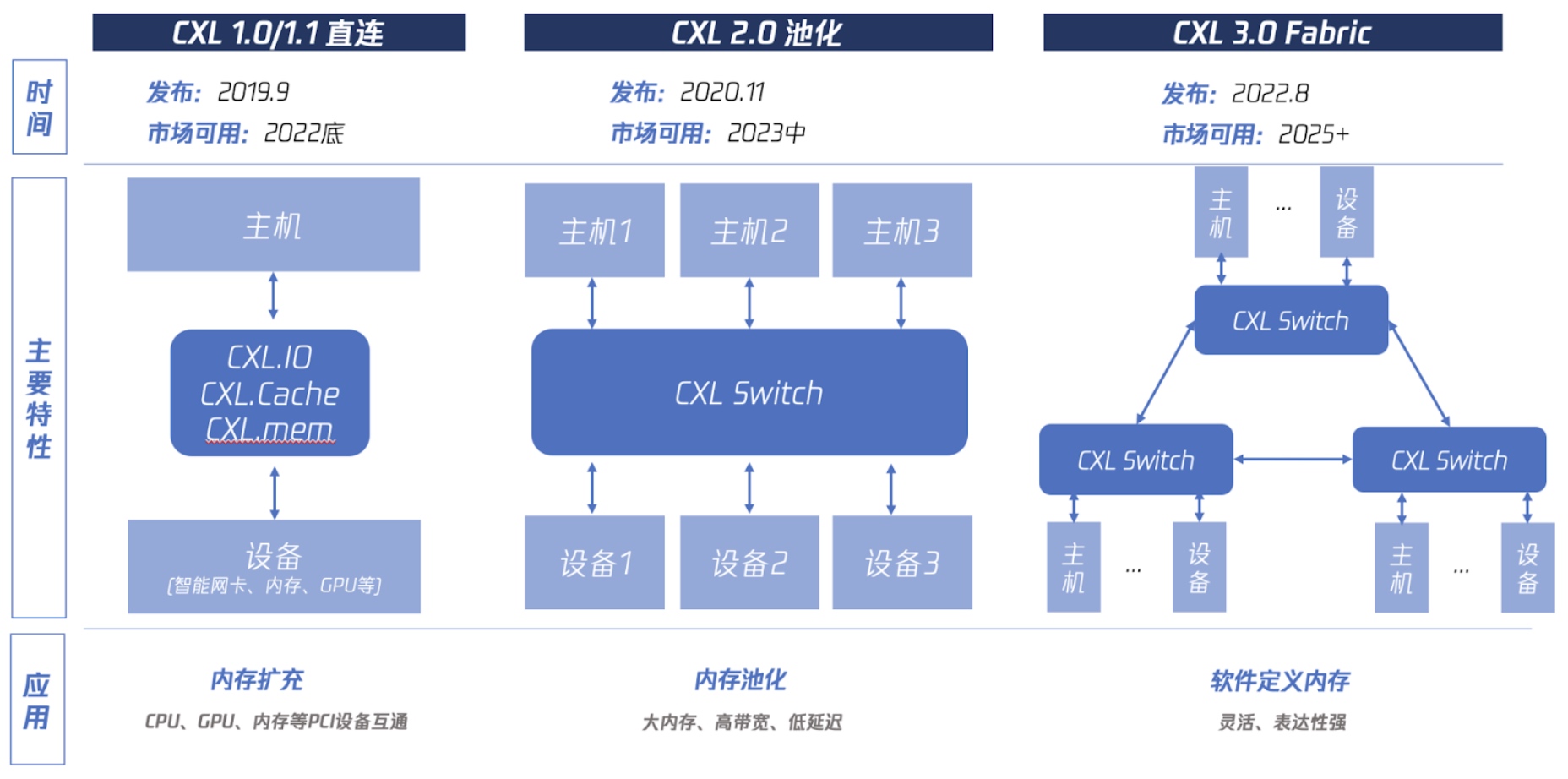
CXL 1 时代主要解决的是基本功能,2.0 要实现类似于 SAN 交换机技术的多对多内存池化,3.0 要构建 CXL 互联网络:实现软件定义内存集群,简单来说,就像上面说的那个分布式存储一样,用软件把内存给集群化。
内存被软件给集群化之后,还会给数据库架构带来巨大的变化:现在基于独立的 RDMA 网卡技术的计算与存储分离架构已经涌现出了 Snowflake、Amazon Aurora、阿里云 PolarDB 等优秀的商用数据库产品,如果内存都能被集群化,那“计算与存储分离”中的“计算”也会被颠覆,届时,“主从同步”四个字将会拥有全新的意义。
超高速网卡也需要 CXL 来解决
当下,x86 服务器界的各路厂商,都在绞尽脑汁地想办法将 400G 网卡塞进机箱。如果说,在不进行任何优化的情况下,利用 Linux 网络栈跑 TCP 只能跑到 5G 是因为软件架构的话,那 400G 网卡用不了就是纯纯的硬件限制了:400G 已经比八路内存的理论带宽都要高了,只要网卡数据还需要经过 CPU,只要还在用 DDR4/DDR5 内存,那 400G 网卡就是非常难以实现的。
CXL 技术给出了 400G 网卡的解决方案:将网卡和 CPU 分离,让他们各自拥有自己的内存空间,并且让 CPU 可以无障碍读写网卡芯片的内存空间。本质上,相当于重新定义了“网卡接到数据后存入内存”这句话里面“内存”二字的含义。
这个思想其实我们早就见识过了:浮点运算能力数百倍于 CPU 的 GPU,就是单独设计内存架构(称为显存),在自己体系内实现了超高性能的,然后直接使用 DP 协议输出 8K 画面,不需要让大量数据经过 CPU 和内存,就不会有性能瓶颈。
x86 内存技术演进番外篇
1. 最近十年内存其实一直在变慢
我们都知道,最近 10 年服务器 CPU 的核数开始爆炸,内存通道也从最开始的双通道一步一步发展到了今天的 12 通道,但是,和内存带宽比,还是 CPU 核数增长的更快一些:这些年,每个 CPU 核心能够分到的内存带宽一直在持续下降,这相当于每台虚拟机能使用的内存读写速度反而在变慢。
2. 英特尔对于 x86 内存体系的限制
前几年,微软统计了自己的服务器各项部件的总成本,惊讶地发现超过 50% 的服务器费用都拿来买内存条了³。内存不仅硬件成本高,现有的内存架构还让内存在虚拟机内部存在巨大的浪费:几乎每台物理服务器都浪费了大约 50% 的内存。而这其实是英特尔故意的。
x86 的内存子系统一直保持着封闭,直到这几年机器学习的崛起让人类社会对于服务器内存的需求又上了一个台阶,在英伟达的股价一次次冲高以后,英特尔才被迫开放了 CXL 标准,基于 PCIe 5.0 的高带宽,才让内存能够像硬盘一样自由扩充。
还记得我们的目标吗?一百万 QPS
一百万 QPS 的 API,在经过性能优化的电商业务中,我们假设每次 API 调用平均执行五条 SQL,那数据库 QPS 就是 500 万。稍微接触过一些高并发系统的人都能一眼看出,这是一个多么惊人的数字,对于开源 MySQL 来说,单机一万的 QPS 就已经非常惊人,500 万,简直就像开玩笑。别急,慢慢往后看,这真的有可能实现。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博